
블로그 이름 뭐하지
[JAVA] 컬렉션 본문
고도화 시킨 배열로, 참조형 변수만 저장한다.
다수의 참조형 데이터를 효과적으로 처리하는 기능을 많이 가지고 있다.
어떤 자료형이라도 담을 수 있으며 크기가 가변적이다.
컬렉션의 종류
| 컬렉션 | 설명 | ||
| List | 데이터를 순서에 따라 관리한다 | ArrayList | 배열처럼 일렬로 데이터를 저장. 인덱스로 조회 |
| LinkedList | 메모리 남는 공간에 나누어 값을 담고 주소값으로 목록 저장. | ||
| Vector | ArrayList와 비슷하나 속도가 느리다 | ||
| Set | 집합. 중복이 허용되지 않는 데이터를 관리한다. | HashSet | 무작위로 값을 담는다 |
| LinkedHashSet | 넣은 순서대로 값을 담는다 | ||
| TreeSet | 자동 정렬하여 값을 담는다 | ||
| Map | Key와 Value로 데이터를 관리하며 Key값은 중복을 허용하지 않는다. | HashMap | 무작위로 키와 값을 담는다 |
| LinkedMap | 넣은 순서대로 키와 값을 담는다 | ||
| TreeMap | 키 값으로 정렬하여 값을 담는다 | ||
| Queue | 데이터를 FIFO(First in First Out) 방식으로 관리한다. (파이프) | ||
| Stack | 데이터를 LIFO(Last in First Out) 방식으로 관리한다. (프링글스 통) | ||
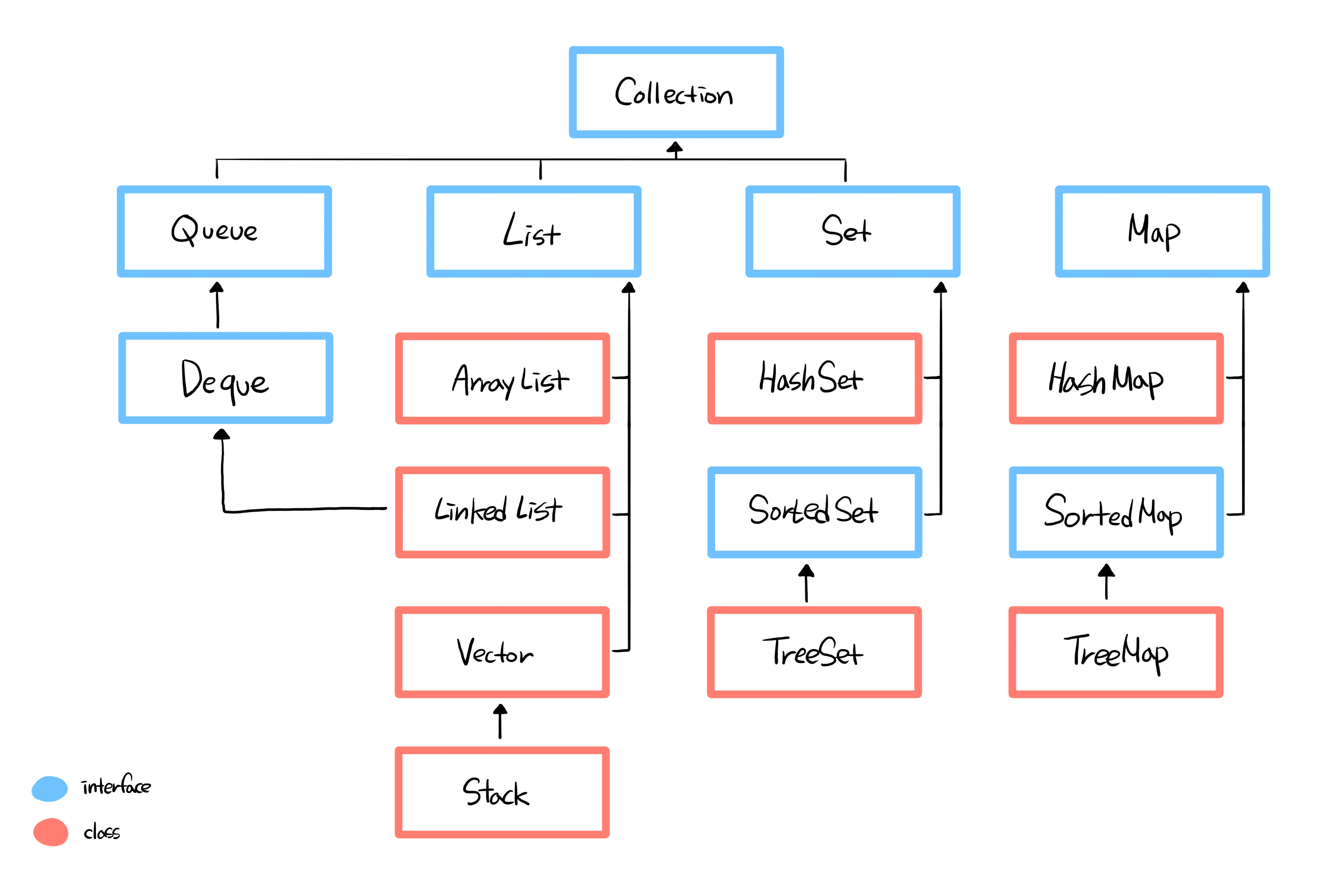
List, Set, Queue는 모두 Collection 인터페이스를 상속받고 있으므로 Collection 인터페이스가 가지는 공통된 메서드를 사용할 수 있다.
컬렉션의 주요 메서드
| 메서드 | 설명 |
| .add(E e) | 데이터 객체 e를 추가 |
| .addAll(Collection<? extends E> c) | 컬렉션 c의 모든 데이터 추가 |
| .contains(Object o) | 객체 o의 포함여부 확인 |
| .containsAll(Collection<?> c) | 컬렉션 c의 모든 데이터가 포함되어 있는지 확인 |
| .remove(Object o) | 객체 o를 삭제 |
| .removeAll(Collection<?> c) | 컬렉션 c와 일치하는 데이터 삭제 |
| .retainAll(Collection<?> c) | 컬렉션 c와 일치하는 데이터를 제외하고 모두 삭제 |
| .clear() | 모든 데이터를 삭제 |
| .size() | 데이터 개수 반환 |
| .isEmpty() | 컬렉션이 비어있는지 여부 확인 |
| .iterator() | 컬렉션의 모든 요소에 대한 iterator(반복자)를 반환 |
| .toArray() | 컬렉션의 모든 요소들을 배열로 반환 |
| .toArray(T[] t) | 현재 컬렉션에 저장된 요소들을 배열 t에 담고 배열 t를 반환 |
List
순서가 유지되고 중복이 허용되는 데이터의 집합(배열과 비슷함)
주요 메서드
| 메서드 | 설명 |
| .add(int index, E e) | 지정된 위치(index)에 요소 저장 |
| .get(int index) | 지정된 위치의 요소 꺼냄 |
| .remove(int index) | 지정된 위치의 요소 삭제 |
| .set(int index, E e) | 지정된 위치의 요소를 새 요소로 교체 |
| .toString() | 전체 값을 대괄호[]로 묶어 출력 |
1. ArrayList
배열처럼 일렬로 데이터를 저장하고 인덱스로 값을 하나씩 조회할 수 있다.
크기가 정해져 있지 않고 필요할 때마다 가변적으로 크기가 늘어난다.(동적배열)
조회는 빠르지만, 추가나 삭제는 느리다.
// ArrayList
import java.util.ArrayList;
public class Main {
public static void main(String[] args) {
// 선언 및 생성
ArrayList<Integer> intList = new ArrayList<Integer>();
intList.add(1);
intList.add(2);
intList.add(3);
System.out.println(intList.get(0)); // 1 출력
System.out.println(intList.get(1)); // 2 출력
System.out.println(intList.get(2)); // 3 출력
System.out.println(intList.toString()); // [1,2,3] 출력
intList.set(1, 10); // 1번순번의 값을 10으로 수정
System.out.println(intList.get(1)); // 10 출력
intList.remove(1); // 1번순번의 값을 삭제
System.out.println(intList.toString()); // [1,3] 출력
intList.clear(); // 전체 값을 삭제
System.out.println(intList.toString()); // [] 출력
}
}
2. LinkedList
메모리에 남는 공간을 요청해 여기저기에 실제 값을 담아두고 주소값으로 목록을 구성하고 저장한다
조회는 느리나 추가, 삭제는 빠르다.
// LinkedList
import java.util.LinkedList;
public class Main {
public static void main(String[] args) {
// 선언 및 생성
LinkedList<Integer> linkedList = new LinkedList<>();
linkedList.add(1);
linkedList.add(2);
linkedList.add(3);
System.out.println(linkedList.get(0)); // 1 출력
System.out.println(linkedList.get(1)); // 2 출력
System.out.println(linkedList.get(2)); // 3 출력
System.out.println(linkedList.toString());
// [1,2,3] 출력 (속도 느림)
linkedList.add(2, 4); // 2번 순번에 4 값을 추가
System.out.println(linkedList); // [1,2,4,3] 출력
linkedList.set(1, 10); // 1번순번의 값을 10으로 수정
System.out.println(linkedList.get(1)); // 10 출력
linkedList.remove(1); // 1번순번의 값을 삭제
System.out.println(linkedList); // [1,4,3] 출력
linkedList.clear(); // 전체 값을 삭제
System.out.println(linkedList); // [] 출력
}
}
3. Vector
구성이나 구조는 ArrayList와 거의 같다.
다만 다른 것은 메서드에 synchronized 키워드 유무로, synchronized는 해당 쓰레드가 실행되는 동안 다른 쓰레드가 접근하지 못하게 만드는 기능이다. 즉, Vector는 멀티쓰레드 환경에서 사용하기 좋다. 하지만 이 때문에 속도가 느리다.
List와 다른 Vector의 메서드
| 메서드 | 설명 |
| .removeAllElements() | 요소만 지우는 clear()와 달리 요소도 지우고, 용량도 0으로 만든다. |
| .capacity() | vactor의 용량을 반환한다(<-> size() 요소의 개수를 반환한다) |
// Vector
import java.util.Vector;
public class Main {
public static void main(String[] args) {
// 선언 및 생성
Vector<Integer> v = new Vector<>(10);
v.add(1);//추가
v.add(2);
v.add(2, 3);//index 3에 값 4 추가
System.out.println(v.get(0)); // 1 출력
System.out.println(v.get(1)); // 2 출력
System.out.println(v.get(2)); // 3 출력
System.out.println(v); // [1,2,3] 출력
v.set(1, 10); // 1번순번의 값을 10으로 수정
System.out.println(v.get(1)); // 10 출력
v.remove(1); // 1번순번의 값을 삭제
System.out.println(v); // [1,3] 출력
v.clear(); // 전체 요소를 삭제
System.out.println(v.size()); // 요소 개수 : 0 출력
System.out.println(v.capacity()); // 용량 : 10 출력
//전체 요소 제거 + 용량도 0으로 만듦
v.removeAllElements();
System.out.println(v.capacity()); // 용량 : 0 출력
}
}
4. Stack
수직으로 값을 쌓아두고 넣었다가 빼서 조회하는 형식(프링글스 통)으로 데이터를 관리
나중에 들어간 것이 가장 먼저 나오는 성질(LIFO)을 가짐
Stack에서 사용하는 메서드
| 메서드 | 설명 |
| .push(E e) | 값을 추가한다 |
| .peek() | 맨 위의 값(가장 나중에 들어간 값)을 조회한다 |
| .pop() | 맨 위의 값을 꺼낸다(삭제) |
// Stack
import java.util.Stack;
public class Main {
public static void main(String[] args) {
// 선언 및 생성
Stack<Integer> intStack = new Stack<Integer>();
intStack.push(1);
intStack.push(2);
intStack.push(3);
while (!intStack.isEmpty()) { // 다 지워질때까지 출력
System.out.println(intStack.pop()); // 3,2,1 출력
}
// 다시 추가
intStack.push(1);
intStack.push(2);
intStack.push(3);
// peek()
System.out.println(intStack.peek()); // 3 출력
System.out.println(intStack.size());
// 3 출력 (peek() 할때 삭제 안됐음)
// pop()
System.out.println(intStack.pop()); // 3 출력
System.out.println(intStack.size());
// 2 출력 (pop() 할때 삭제 됐음)
}
}
Queue
한쪽에서 데이터를 넣고 바깥쪽에서 데이터를 뺄 수 있는 집합(파이프)
먼저 들어간 순서대로 값을 조회할 수 있다.(FIFO)
생성자가 없는 껍데기이므로 LinkedList를 통해 생성이 가능하다.
Queue에서 사용하는 메서드
| 메서드 | 설명 |
| .add(E e) | 값을 추가한다 |
| .peek() | 맨 아래값(가장 처음에 넣은 값)을 조회한다 |
| .poll() | 맨 아래 값을 꺼낸다(삭제) |
// Queue
import java.util.LinkedList;
import java.util.Queue;
public class Main {
public static void main(String[] args) {
// 선언 및 생성
Queue<Integer> intQueue = new LinkedList<>();
intQueue.add(1);
intQueue.add(2);
intQueue.add(3);
while (!intQueue.isEmpty()) { // 다 지워질때까지 출력
System.out.println(intQueue.poll());
// 1,2,3 출력
}
// 다시 추가
intQueue.add(1);
intQueue.add(2);
intQueue.add(3);
// peek()
System.out.println(intQueue.peek());
// 1 출력 (맨 먼저 들어간 값이 1 이라서)
System.out.println(intQueue.size());
// 3 출력 (peek() 할때 삭제 안됐음)
// poll()
System.out.println(intQueue.poll()); // 1 출력
System.out.println(intQueue.size());
// 2 출력 (poll() 할때 삭제 됐음)
}
}
Set
순서가 없고 중복이 없는 배열
생성자가 없는 껍데기이므로 HashSet를 통해 생성이 가능하다.
| Set의 종류 | 설명 |
| HashSet | 가장 빠르고 순서를 예측할 수 없음 |
| TreeSet | 정렬된 순서대로 보관하며, 정렬 방법을 지정가능 |
| LinkedHashSet | 추가된 순서, 또는 가장 최근에 접근한 순서대로 접근가능 (순서보장이 필요할 시 LinkedHashSet을 쓴다) |
// Set
import java.util.HashSet;
import java.util.Set;
public class Main {
public static void main(String[] args) {
// 선언 및 생성
Set<Integer> intSet = new HashSet<Integer>();
intSet.add(1);
intSet.add(2);
intSet.add(3);
intSet.add(3); // 중복된 값은 덮어쓴다
intSet.add(3); // 중복된 값은 덮어쓴다
for (Integer value : intSet) {
System.out.println(value); // 1,2,3 출력
}
// contains()
System.out.println(intSet.contains(2)); // true 출력
System.out.println(intSet.contains(4)); // false 출력
// remove()
intSet.remove(3); // 3 삭제
for (Integer value : intSet) {
System.out.println(value); // 1,2 출력
}
}
}
Map
key-value 구조로 구성된 데이터
key값을 기준으로 value를 조회하며, key값은 중복을 허용하지 않는다.
| Map의 종류 | 설명 |
| HashMap | 중복 허용하지 않고 순서 보장하지 않음, 키와 값으로 null이 허용됨 |
| TreeMap | key값 기준으로 정렬 가능, 저장시 정렬(오름차순)하므로 저장시간이 오래걸림 |
Map에서 사용하는 메서드
| 메서드 | 설명 |
| .put(key, value) | key에 value값을 추가한다 |
| .get(key) | 해당 key에 있는 value값을 조회한다 |
| .keySet() | 전체 key값을 조회한다 |
| .values() | 전체 value값을 조회한다 |
| .remove(key) | 해당 key에 있는 value값을 삭제한다 |
// Map
import java.util.Map;
public class Main {
public static void main(String[] args) {
// 선언 및 생성
Map<String, Integer> intMap = new HashMap<>();
// 키 , 값
intMap.put("일", 11);
intMap.put("이", 12);
intMap.put("삼", 13);
intMap.put("삼", 14); // 중복 Key값은 덮어쓴다
intMap.put("삼", 15); // 중복 Key값은 덮어쓴다
// key 값 전체 출력
for (String key : intMap.keySet()) {
System.out.println(key); // 일,이,삼 출력
}
// value 값 전체 출력
for (Integer key : intMap.values()) {
System.out.println(key); // 11,12,15 출력
}
// get()
System.out.println(intMap.get("삼")); // 15 출력
}
}'JAVA' 카테고리의 다른 글
| [JAVA] 클래스 (0) | 2024.09.23 |
|---|---|
| [JAVA] 객체 지향 프로그래밍의 이해 (1) | 2024.09.20 |
| [JAVA] 배열 (0) | 2024.09.20 |
| [JAVA] 조건문, 반복문 (0) | 2024.09.20 |
| [JAVA] 연산자 (2) | 2024.09.19 |

